Le premier objectif est d’améliorer les données textuelles obtenues par des transcriptions automatiques (par reconnaissance de caractères), en mettant à profit les méthodes d’apprentissage profond. Il s’agit de paramétrer finement la reconnaissance automatique des caractères originaux figurant dans l’imprimé ancien. Cecorpus pilote de Mazarinades étant constitué de textes d’actualité, il ne prend sens qu’en le situant dans la production textuelle contemporaine : aussi convient-il d’intégrer de larges ensembles d’écrits du 17e siècle, disponibles sur les grandes bibliothèques numériques. Un des buts du projet est ainsi d’abonder une de ces bibliothèques numériques, celle de la Bibliothèque Mazarine, en favorisant les numérisations puis en automatisant le passage du mode image au mode texte. S’ensuivent plusieurs pistes de travail, comme la myriadisation pour la normalisation du mode texte, ainsi que divers types d’annotations, de balisage et d’extractions d’informations comme les entités nommées.
Le second objectif regroupe une série d’applications en Traitement Automatique des Langues, notamment la datation automatique, l’attribution d’auteur ainsi que la classification non-supervisée. Ces expériences exploiteront d’abord directement les données brutes (sorties d’OCR bruitées), dont l’analyse au grain caractère peut produire des résultats parfois meilleurs que les données lissées pour l’oeil humain, bien plus coûteuses pourtant à obtenir.
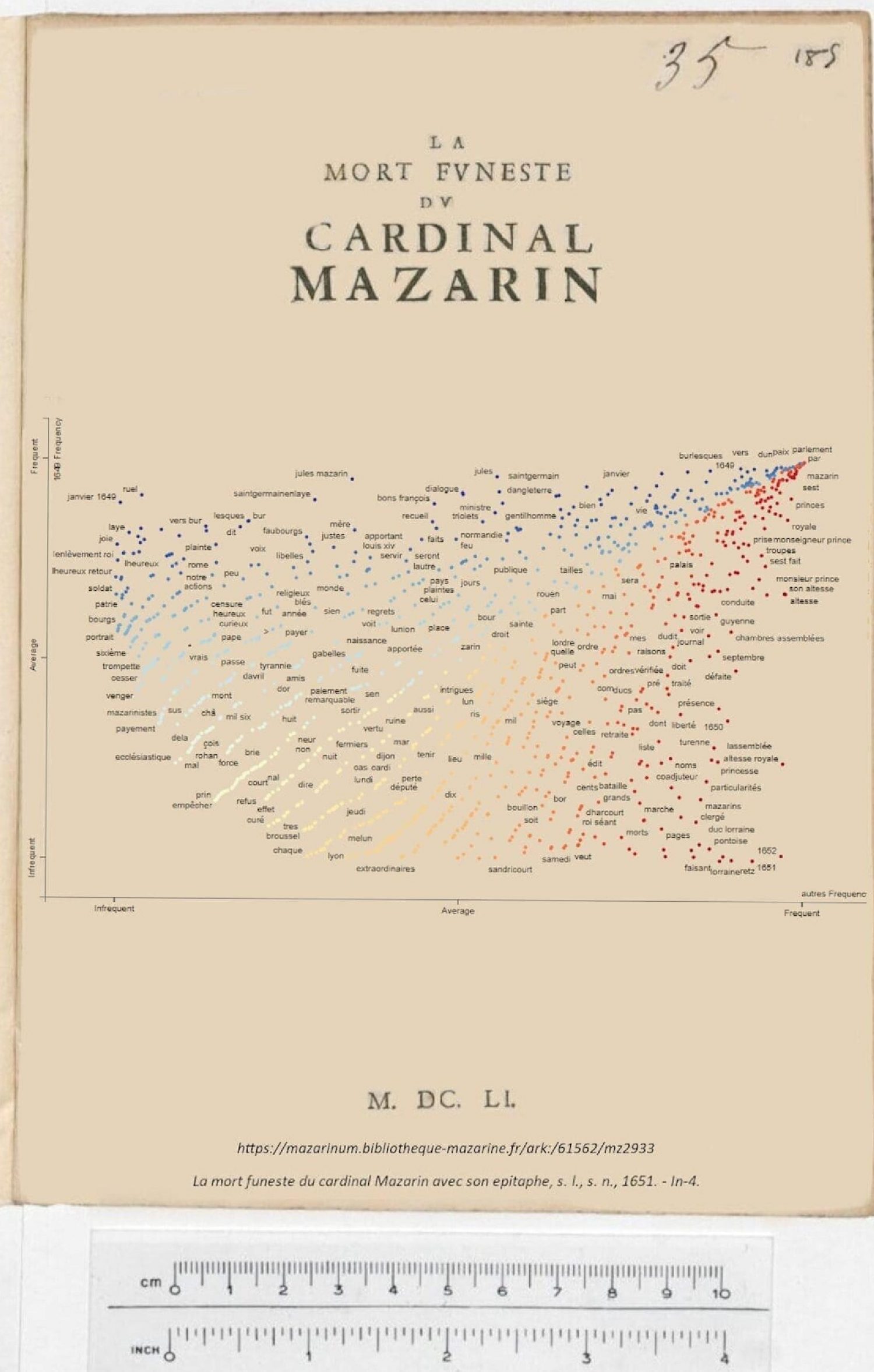
Le troisième objectif est de proposer une visualisation originale de ces textes polémiques qui, en raison de leur nature réactionnelle, n’ont de sens que par leur mise en réseaux. Il s’agira de rendre compte de leur enchaînement à la fois chronologique et réticulaire.